With artificial intelligence and its many variants becoming core parts of our products, we need to think about how to onboard users to automated experiences. The principles that underpin good user onboarding for AI aren’t that different from the principles that underpin good user onboarding for anything else. But, because of the unpredictable nature of AI, we must embrace interactive, multi-part guidance more than ever before, instead of the information-heavy approaches that still dominate onboarding for traditional products today.

When can onboarding help an AI experience?
Whether the use of AI would benefit from an onboarding experience depends on how novel that experience is compared to people’s expectations.
Straightforward implementations of AI, therefore, may not require onboarding. Duolingo, which uses quizzes to teach people a new language, uses deep learning to adjust to the pace of learners, allowing it to personalize which question to show them next. While Duolingo may have a higher-level onboarding experience about its general teaching process, it wouldn’t need to familiarize the user with the idea that it auto-generates the next question in a quiz. This is because the end result for the user is not surprising; they are still experiencing a language-learning quiz.
But if an implementation of AI will require novel interaction, generate unexpected results, or be processing a user’s personally identifiable data in surprising ways, an onboarding experience should be considered. Automation may seem like a magical solution, but there are consequences if users don’t understand what’s happening. Lack of comprehension can erode trust, causing new and existing users to leave.
According to a variety of sources, including Josh Clark and the Google AI design series, to be successful, AI experiences must:
- Familiarize, by setting expectations about what it can do and how it helps the user.
- Build trust, by being transparent about how results are generated and getting the user’s consent if their data is involved.
- Adapt to an individual user’s needs through calibration
- Guide them to their next steps, by helping users do more with the experience and understand future enhancements or changes
Compare this to user onboarding, which is the process of acclimating a person to a new experience by guiding them through multiple interactions over time. Its jobs are also fourfold:
- It needs to familiarize new users with the current and potential capabilities of a new product or service
- It needs to build trust
- It needs to learn about users, to tailor an experience to their needs
- And it must guide them to their next steps toward success (for them, and for us!)
Clearly, there’s an overlap in what good onboarding provides and what good AI needs.
By taking time to onboard users to an AI-driven feature or experience, we can improve their interaction with it, build trust, and ensure that they meet their goals with this powerful new piece of technology. This can also lay a foundation for future positive interactions with AI.
I’ve written a lot about how using in-situ, interactive approaches allows onboarding do its jobs effectively. Let me share how these approaches can help us build good onboarding to artificial intelligence.
Guided interaction for AI experiences
You might hope to familiarize new users with your machine intelligence features by explaining all the details up front, before they start using the product. Perhaps it’s because you want to sell them by describing the juicy, technical details. Or, perhaps your experience has some boundaries, like a chatbot with a limited set of replies, and you want to ensure users know the rules of engagement before they get started.
But most users won’t bother to learn all about an AI before they start using it (save from extremely curious folks with a lot of time on their hands). They don’t read the manual, watch videos, or internalize slideshow descriptions before they start using something, even if it would be in their best interest, or even if they paid for it. Passive, explanatory introductions are not the way to go.
Also, automated experiences can be unpredictable. An AI is trained to take in data, recognize patterns, and generate results within a set of success criteria. Results often differ from situation to situation and from person to person. Even with the most carefully designed training criteria that give us confidence the results will fall within some expected range, we can’t predict them with 100% certainty. As Josh Clark, author of Designing with Artificial Intelligence: The Dinosaur on a Surfboard, says, “One of the things I’m finding as we begin to design for data-generated content and interaction, is that much of the work is actually just trying to anticipate the weirdness that comes out of these machines. […]”
If we, the architects of automated experiences, can’t even predict what results might come from them, how can we expect to explain it to our new users before they’ve used it?
This is where guided interaction comes in. It’s based on an interactive educational design principle called the guided activity principle, which says that people learn more effectively when interacting with guidance, instead of just being shown pure information, or being engaged in pure discovery. An “interact, don’t tell” design principle one I’ve advocated for years, but is now imperative as the many variants of AI make their way into our experiences.
Reactive guidance
One effective way to implement guided interaction is through reactive guidance. This is when you teach someone about something after they interact with it. This embraces a learning-by-doing approach and can be great for familiarizing users to AI features added to existing experiences. This fits the AI model quite well, in that seeing or experiencing the results of an AI experience can make the concepts we want people to reflect on less abstract.
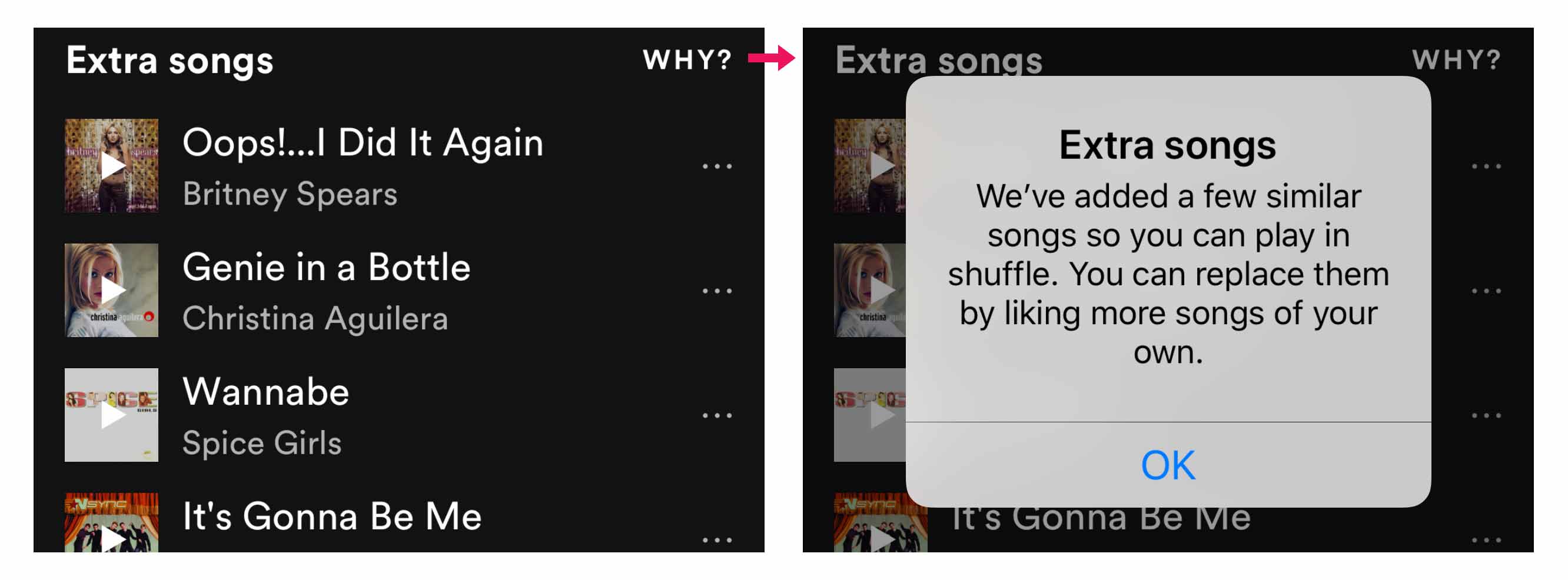

Once results are seen, it’s easier for the user to comprehend what’s happening and make decisions on it. They can decide whether they want to continue, stop, or tweak the results.
Retroactive consent
Retroactive consent is the act of asking a user if they want to continue with an experience, after it happens. A concept that might be hard to explain upfront can be demonstrated in the context of the user’s interaction, making it easier for them to decide whether to keep going with it.

Retroactive consent doesn’t have to be limited to a yes/no choice. We can also use retroactive consent allow people to calibrate an AI. Perhaps a person is OK with the general concept of a an experience, but the results aren’t yet quite as good as they expected. Retroactive consent can let them give feedback to the AI in a way that improves their future results.

If you do leverage retroactive consent, ensure that there is a route for a user to completely revoke or change any personal data that was used to achieve such a result.
While reactive guidance and retroactive consent can be effective methods, if an AI experience is going to be processing personal data, neither of these methods should be the first time users become aware of this. Proactive guidance should be used ahead of an experience to garner initial consent for data usage. One of the best ways to build proactive guidance is with free samples.
Proactive guidance with free samples
Onboarding can lay a foundation for trust early in an experience by setting expectations about how a user’s data might be used in relation to the user’s goals. From a Google Design post about the UX of AI: “If the goals of an AI system are opaque, and the user’s understanding of their role in calibrating that system are unclear, they will develop a mental model that suits their folk theories about AI, and their trust will be affected.”
Some try to achieve transparency with cursory videos or marketing content providing the promise of the product, followed by a Privacy Policy link next to an “Agree” or “Sign up” button. Some are trying to go further: IBM has proposed using standardized factsheets to give customers details about how an AI works. While we should be ready to explain how our AI works, relying only on these tactics to achieve informed, up-front consent is just like relying on users to read the manual. Users either won’t read it, or the concepts will be too abstract for them to make a good decision. This can result in abandoned products or the provision of false information by untrusting users.
So, how do we proactively inform users about the use of their personal data, before they commit to our products, without relying on passive explanations? By providing free samples. Free samples let a person interact with some part of an AI experience that demonstrates its capabilities using no to little personally identifiable information (PII).*
Note: I am not a lawyer, so the following examples are not to be considered guidance on what is or isn’t PII for your product or jurisdiction.
Buoy Health is a web-based virtual medical advice assistant aimed at employees at workplaces. While it’s intended to be used in a signed-in state, allowing users to save ongoing health profiles, they allow people to “try before they buy.” New users can try out the technology by checking their symptoms account-free.


Compare this free sample experience to AI assistants that force users to create an account before they can do anything. The latter requires a much bigger leap of faith.

Another way to provide free samples is by creating standalone demos outside of an existing product suite. Companies like Google and Microsoft publish experiments that demonstrate the different capabilities of AI. These experiments can help familiarize users with novel concepts in low-risk ways, so that they’re better informed if those concepts are introduced in a day-to-day product.
An example is Google’s AutoDraw tool, a browser-based drawing interface that shows how machine learning can suggest artist-rendered clipart replacements for hand-drawn doodles. This can help build familiarity with and trust for the capabilities (and limitations) of the kinds of image recognition that might show up in their products.

Free samples can lay a foundation of trust by giving users an opportunity to try an AI experience before committing to an experience. While it doesn’t replace the need to have human-parseable explanations about how the AI works, it can help us better inform our users and help them understand the potential outcomes of the experience.
Even if we achieve user comprehension and informed consent up front, we still must give people the opportunity to change their minds afterwards. We can thus pair retroactive consent with proactive free samples. It’s a bit like providing a flexible return policy on an online purchase: A user may be more likely to buy an item if they know they have the option to return it later.
Continued guidance and reinforcement
Using reactive guidance, retroactive consent, and proactive free samples can help onboard users to an AI experience and pave the way for trust, engagement, and retention. But it takes more than a single instance of guidance to achieve this. We need to continue reinforcing the goals, implications, and capabilities of our AI, and guide users to their next steps.
In the education world, there is the concept of spaced repetition, also covered relative to user onboarding in a previous post. This is when a learner is repeatedly exposed to a concept at intervals spaced out over time, after their initial exposure. This is a more effective method of learning compared to “cram” information in all at one time (and is yet another reason why up-front explanations often fail). But, because our product lives amidst many other distractions in a user’s life, we can’t just badger the user with mindless repetition. Instead, onboarding should aim to *reinforce* concepts by using different methods, at different times.
Consider how Amazon continually reinforces Alexa’s wide range of capabilities across multiple surfaces:

Using multiple surfaces also gives Amazon the benefit of communicating the new capabilities of Alexa, as well as reinforcing existing ones, so that users in different situations will be exposed to them. Building onboarding in a way that considers many techniques and surfaces over time gives us a means for communicating new capabilities, asking for further calibration, or guiding users to next steps.
Break things down
To help you figure out where to apply guidance in an AI-driven experience in a way that considers a user’s next steps, I suggest breaking each feature or action into an onboarding module made of 3 parts:
- The prompt is how the user can initiate an action. Here, guidance can leverage surrounding context to set expectations about what will happen next and introduce the benefits of taking action.
- The work is the meat of an action, and happens once an action is initiated through a prompt. Here, guidance needs to restate the benefits of continuing, provide the skills or knowledge needed to complete the activity, and guide the user through subtasks or errors.
- The follow-up is the state that closes out the action. Here guidance should give feedback about what happened, whether successful or not, and lead the user to their next steps.
Let’s look at how this breakdown might apply to an automated experience. We’ll examine it in the context of a hypothetical medical AI chat bot (these are sketches for demonstration purposes only).


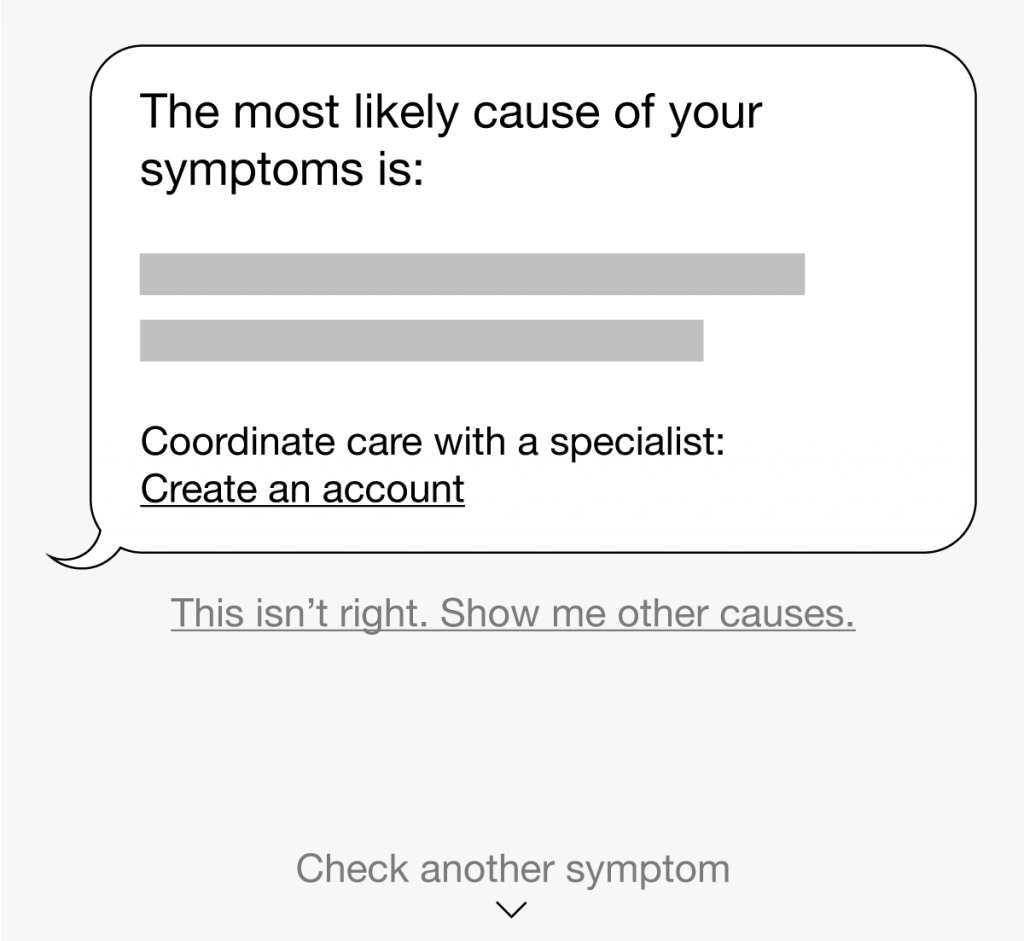
Don’t expect onboarding to solve core issues
Onboarding is an important consideration for improving familiarity with, trust in, calibration of, and continued use of AI experiences. But don’t expect user onboarding to solve inherent design problems with an AI. If users are experiencing big trust or comprehension issues, first check to see if there are any flaws upstream.
In 2018, Tumblr launched a censorship AI feature. It got a lot of bad press for overzealously flagging content that was not actually sensitive, which greatly frustrated their content creators. Sure, Tumblr could have built an onboarding experience to describe the purpose of the AI to content creators and to let them know what to do to avoid being flagged, but the real solution is to tweak the success criteria of the AI to reduce the odds of false positives.
Designers from “Clips,” a Google camera that takes videos and photos offline and uses machine intelligence to suggest the best segments to save, shared how they adjusted the design of their product to improve user trust and comprehension. One of the issues they had to work on was getting users comfortable with the idea of AI suggestions. “…we showed users more moments than what we necessarily thought was just right, because by allowing them to look a bit below the ‘water line’ and delete stuff they didn’t want, they actually developed a better understanding of what the camera was looking for, as well as what they could confidently expect it to capture in the future.” By making a core change in their product, they implicitly improved how users would be onboarded to it, without trying to make onboarding solve the issue for them.
Summary
We can see that many of the principles that underpin good onboarding for any product still apply to onboarding experiences for AI-driven products. Consider how novel the experience is, how surprising the results might be, and how much personal information the AI will process as you design an onboarding experience for it.
And for those wondering if AI can actually be a solution or designing onboarding? Well, that’s a thought-stream for another day…